- Published on
NodeJS中的 Worker 线程
本文翻译至:Worker Threads : Multitasking in NodeJS
目录
- 为什么我们需要 Worker Threads
- 在了解什么是Worker Threads前你需要知道的
- 那到底什么是 Worker Threads 呢?
- 还有一些我们需要知道的
- 原子化
- Worker 线程的使用陷阱
为什么我们需要 Worker Threads
服务器很容易被 CPU 密集型工作负载所淹没。举例来说,假设您有两个终端:一个执行简单的非 CPU 密集型任务,而另一个处理需要 10 秒才能完成的复杂 CPU 密集型任务。
如果您的服务器被 CPU 密集型请求占用,它将无法及时响应非 CPU 密集型请求。之所以出现这个问题,是因为我们违反了 NodeJS 的黄金法则:不要阻塞事件循环。
我们很清楚,由于 NodeJS 的单线程架构,它不是为 CPU 密集型任务而设计的。然而,这并不意味着我们不能利用它进行 CPU 密集型工作,或者享受多线程架构设计带来的好处。解决方案就是:Worker Threads。
Node.js v10.5.0 通过 worker_threads 模块引入了Worker Threads的实验性特性,自 Node.js v12 LTS 起,Worker线程进入Stable。
在了解什么是Worker Threads前你需要知道的
并发与并行
并发是指同时处理很多事情。并行是指同时做很多事情。- Rob Pike
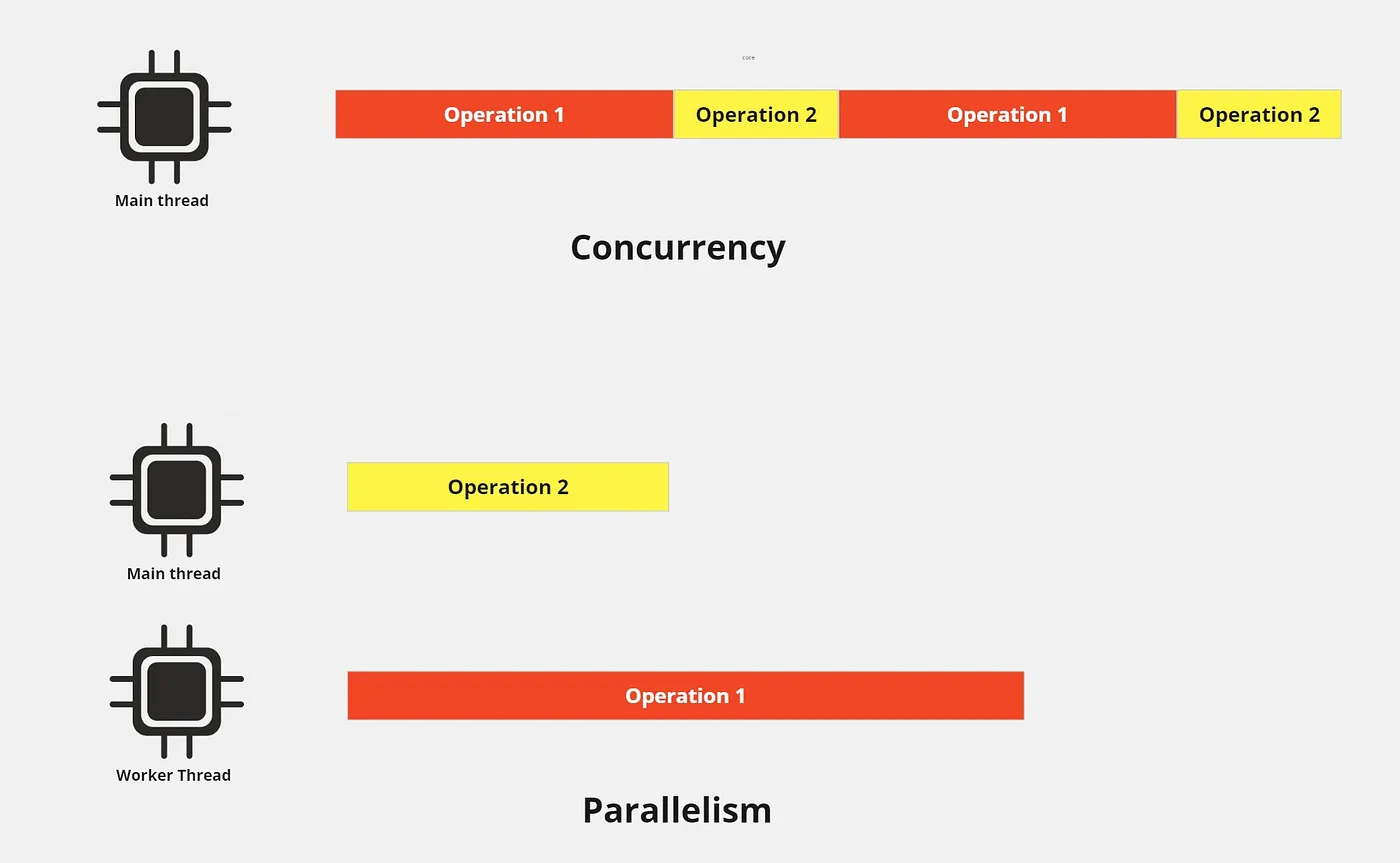 Operation 1 = CPU Intensive, Operation 2 = Non-CPU Intensive
Operation 1 = CPU Intensive, Operation 2 = Non-CPU Intensive
让我们首先了解工作线程的本质:并行性,而不是并发性。如上图所示,与同时执行多个任务(parallelism)相比,使用单个线程执行多个任务(concurrency)需要更多时间。
关于并发与并行:

并发(Concurrent): 是多个队列使用同一个咖啡机,然后两个队列轮换着使用(未必是 1:1 轮换,也可能是其它轮换规则),最终每个人都能接到咖啡
并行(Parallel): 是每个队列都拥有一个咖啡机,最终也是每个人都能接到咖啡,但是效率更高,因为同时可以有两个人在接咖啡
Referer: 并发和并行
并发模型对于网络通信、读取和写入文件/数据库等 IO 操作很有用,因为你正在等待网络或磁盘提供需要处理的实际数据。 CPU 或线程无法做太多的事情来加快速度。所以你的大部分时间都花在了等待上。所以线程可以在这段时间内做其他事情,这更有意义。
不过,这种方法可能不适合 CPU 密集型任务。虽然Operation 2 相对较快,但由于我们只使用了一个core/thread.,因此最终花费了更多时间。通过使用多个线程/内核,我们可以将 CPU 密集型工作委托给工作线程,同时在主线程上运行非 CPU 密集型任务。
在 NodeJS 中,I/O 操作是单独处理的,当它们完成时,事件循环会在I/O队列中添加与 I/O 任务关联的回调。当主线程中的调用堆栈清空时,回调将被推送到调用堆栈上,然后执行。明确这一点,即与给定 I/O 任务关联的回调不会并行执行;不过,读取文件或网络请求的任务本身会在线程的帮助下并行发生。一旦 I/O 任务完成,回调将在主线程中运行。
了解进程和线程
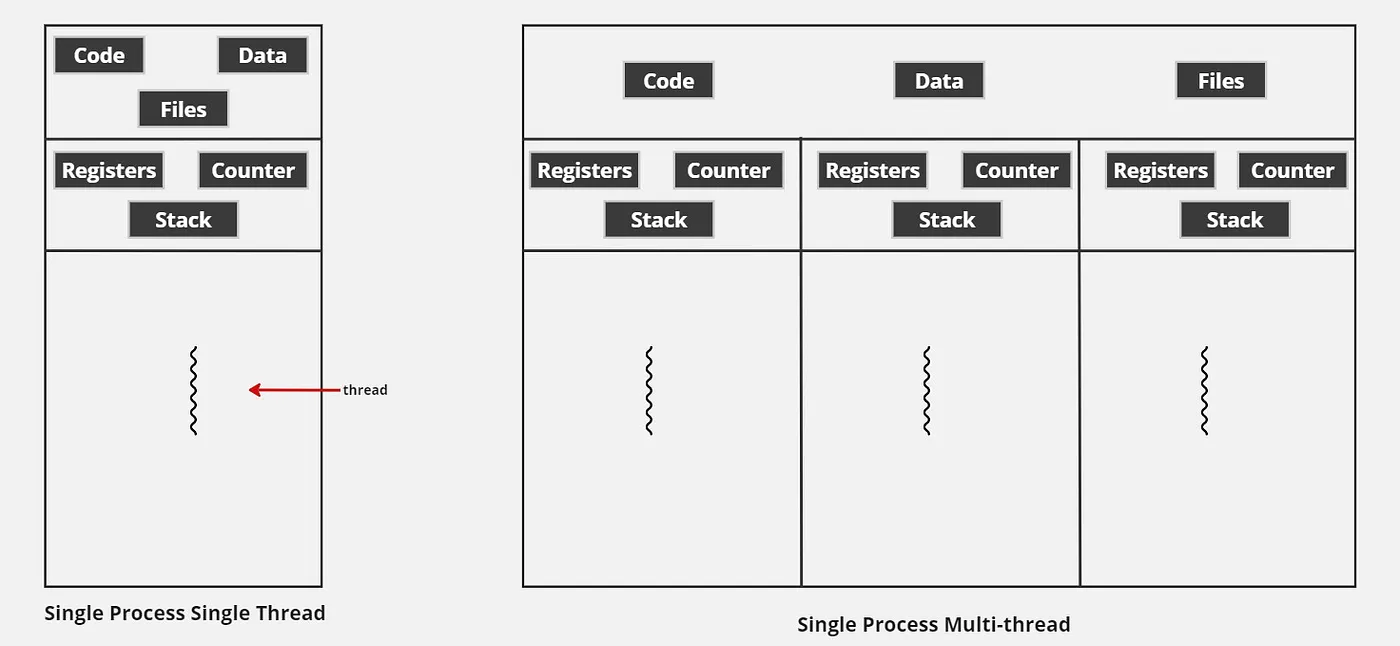
进程是操作系统中正在运行的程序。它有自己的内存,无法看到或访问其他正在运行的程序的内存。一次只能执行一项任务。
在单核计算机上,多个进程同时执行。也就是说,操作系统定期在进程之间进行切换。
在多核计算机上,操作系统安排每个进程同时在每个核上执行。但是,如果创建的进程多于核心数,则每个核心将同时执行多个进程,直到它们完成。
线程就像一次可以执行一项任务的进程。与进程不同,线程没有自己的内存。相反,它们驻留在进程的内存中。
创建进程时,它可以有多个线程并行执行代码。此外,线程可以通过消息传递或共享进程内存中的数据来相互通信。与进程相比,这使得它们变得轻量级,因为生成线程并不要求操作系统提供更多内存。当谈到线程的执行时,它们具有与进程类似的行为。
类比
简而言之,worker threads 就像在餐厅里有额外的厨师和主厨同时准备多盘食物。

那到底什么是 Worker Threads 呢?
在本节中,您将使用 worker-threads 模块将 CPU 密集型任务卸载到另一个线程,以避免阻塞主线程。
为此,您将创建一个包含 CPU 密集型任务的 worker.js 文件。在 parent.js 文件中,您将使用 worker-threads 模块初始化线程,并在 worker.js 文件中启动任务,与主线程并行运行。任务完成后,工作线程将向主线程发送一条包含结果的消息。
// parent.js
const {Worker} = require('worker_threads');
const worker = new Worker('./worker.js', {workerData: {num: 5}});
worker.on('message', (result) => {
console.log('square of 5 is :', result);
})
worker.on("error", (msg) => {
console.log(msg);
});
console.log('hurreyy')
首先,您导入 worker_threads 模块并解构 Worker 类,使用 new 关键字创建 Worker 的实例并调用。参数是 worker.js 文件路径。这将创建一个新线程,worker.js 文件中的代码会在另一个核心上的线程中开始运行。
您可以使用 on("message") 方法将事件附加到 worker 实例以侦听消息事件。当收到包含 worker.js 文件结果的消息时,它会作为参数传递给方法的回调,该回调将包含 CPU 密集型任务的结果的响应返回给用户。
然后使用 on("error") 方法将另一个事件附加到工作实例以侦听错误事件。
// worker.js
const {parentPort, workerData} = require('worker_threads');
parentPort.postMessage(workerData.num * workerData.num)
第一行加载 worker_threads 模块并提取 parentPort 类。该类提供了用于向主线程发送消息的方法。WorkerData 包含线程初始化时从主线程传递的数据。然后调用 parentPort 类中的 postMessage() 方法,向主线程发送message消息事件,并包含一个平方计算结果。
当您使用node parent.js运行parent时,您将看到以下输出:
hurreyy
square of 5 is : 25
发生了什么?
我们现在已经知道,当 NodeJS 进程启动时,它会以一个进程、一个线程、一个Event Loop、一个 V8 引擎实例、一个 Node.js 实例启动。
就像主线程一样,每个Worker Threads在同一进程中都会有自己的 V8 实例、node、libuv 实例和事件循环。
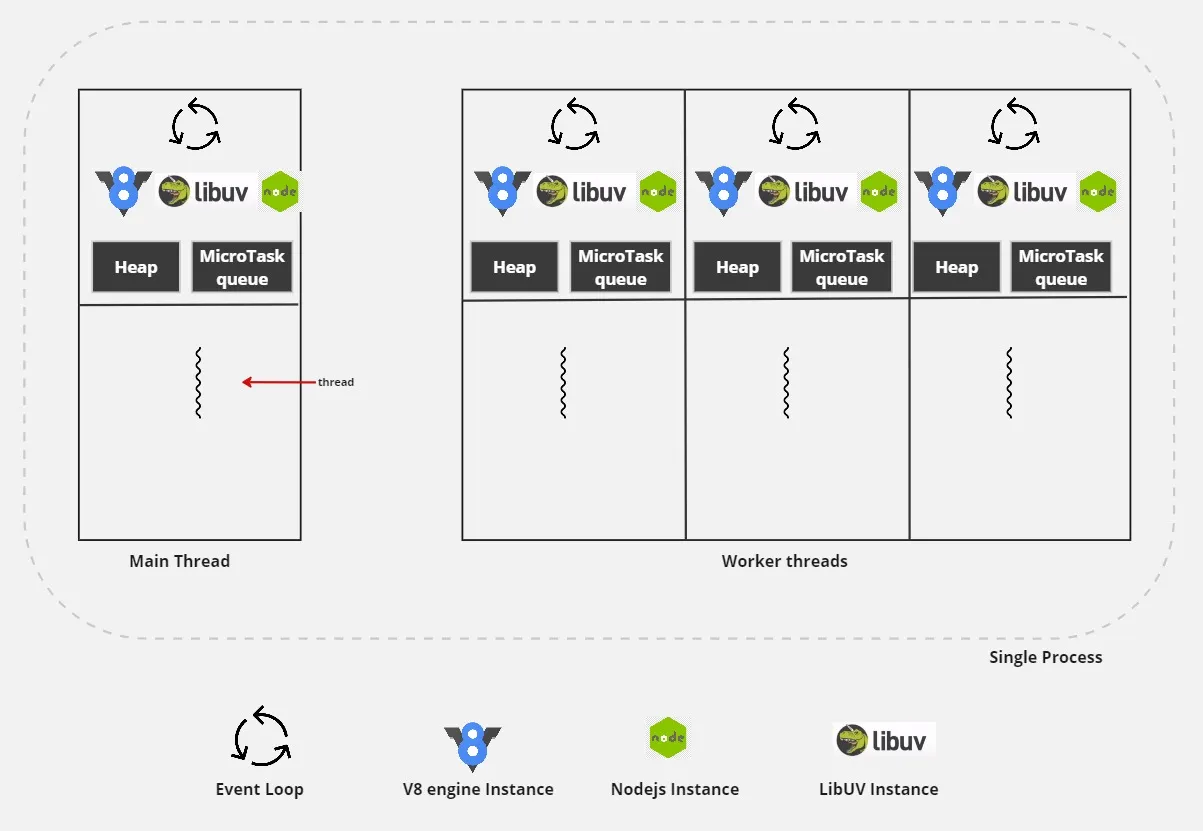
V8 isolate是指 chrome V8 运行时中的独立实体。它拥有自己的 JS 堆和微任务队列。这种独特的设置使每个 Node.js Worker线程能够在与其他Worker线程完全隔离的情况下执行其 JavaScript 代码。
然而,这种隔离是有代价的 —— workers 无法直接访问彼此的堆。因此,每个 workers 都维护自己的 libuv event loop,独立于其他 worker 和 parent worker 的事件循环进行操作。
使用 Worker 线程时,线程可以在某个时间点完成,但不一定是随着父进程的完成。当 Worker线程结束时,让 Worker线程分配的资源闲置起来并不是一个好的做法 —— 这会导致内存泄漏,我们不希望这样。我们希望将Node.js嵌入到自身中,让Node.js能够创建一个新线程,然后在该线程中创建一个新的Node.js实例,实质上在同一进程中运行独立的线程。
worker_threads 通过允许应用程序使用多个隔离的 JavaScript Worker 来提供并发性,其中 Worker 和父 Worker 之间的通信由 Node 提供。主程序和 Worker "线程 "之间不存在隐式内存共享。取而代之的是一个基于事件的消息系统,以便在进程之间交换信息。
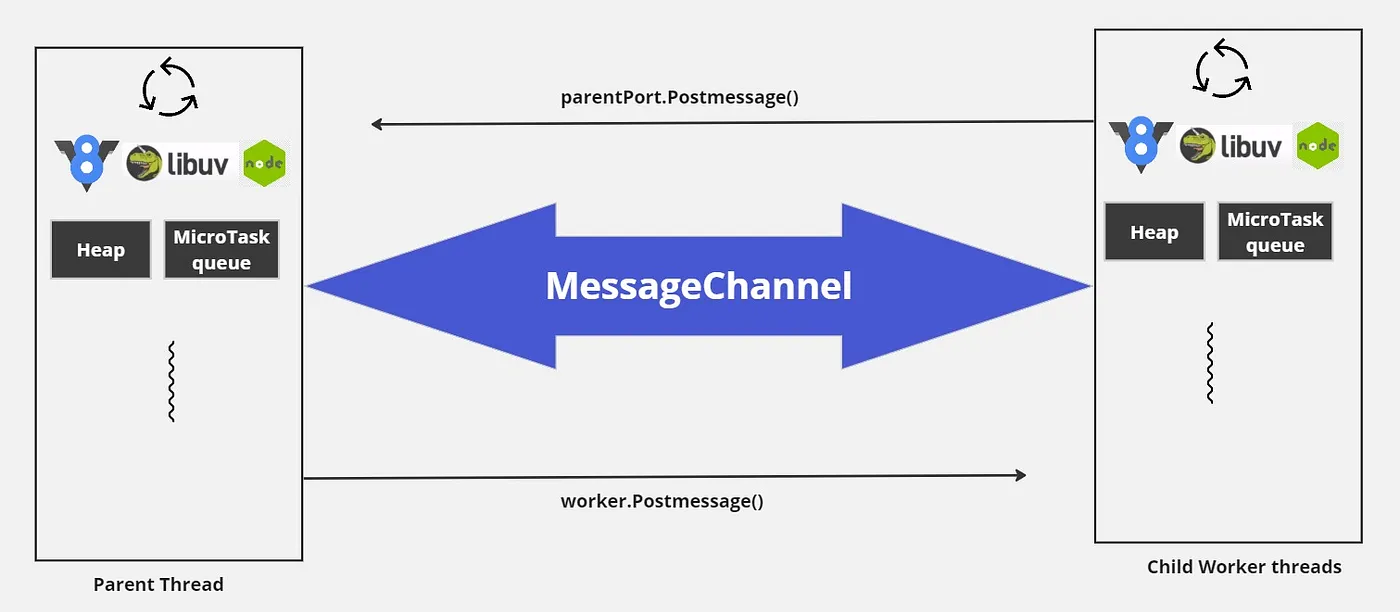 每个 Worker 都通过一个 message channel 连接到 父Worker
每个 Worker 都通过一个 message channel 连接到 父Worker
Worker线程在幕后以两个不同的阶段运行。
- 第一阶段是 Worker 初始化,其中创建Worker实例并建立 父Worker和 子Worker 之间的初始通信。这允许将 Worker元数据 从 父Worker传输到 子Worker。
这个初始化元数据是什么?这是Worker程序执行脚本启动工作程序所需的信息:要成为Worker程序运行的脚本的名称、Worker程序数据和其他详细信息。根据我们的示例,初始化元数据只是一条消息,例如:Hey Worker。
您可以使用worker data {num: 5} 运行 worker-simple.js 吗?
- 第二阶段是 worker execution,其中使用用户提供的 workerData 和 父Worker提供的其他元数据来执行用户的 Worker JavaScript 脚本。这是创建新的 v8 实例并将其分配给 Worker 的地方。然后libuv用它自己的事件循环进行初始化。读取初始化元数据并执行worker.js。
还有一些我们需要知道的
isMainThread, threadId
如果您不想为worker程序创建新文件,您只需传递 __filename 作为worker程序实例化脚本的路径,它将是相同的文件。使用isMainThread ,您可以在主线程和worker线程上分离您想要的逻辑。实例化对象拥有唯一的threadId属性。
worker events
Worker 提供了一些可以与我们想要的回调结合起来的事件:
message :当工作线程调用
parentPort.postMessage()时,会发出 'message' 事件。exit :一旦worker线程停止,就会发出 'exit' 事件。如果worker通过调用
process.exit()来退出,则exitCode参数是传递的退出代码。如果工作线程被终止,则exitCode参数为1。这也是任何 Worker 实例发出的最后一个事件。error :如果worker线程抛出未捕获的异常,则会发出 'error' 事件。在这种情况下,worker将被终止。
online :当worker线程开始执行 JavaScript 代码时,将发出该 'online'事件。
const { Worker, isMainThread, parentPort, workerData } = require('node:worker_threads');
if (isMainThread) {
module.exports = function parseJSAsync(script) {
return new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: script,
});
worker.on('message', resolve);
worker.on('error', reject);
worker.on('exit', (code) => {
if (code !== 0)
reject(new Error(`Worker stopped with exit code ${code}`));
});
});
};
} else {
const { parse } = require('some-js-parsing-library');
const script = workerData;
parentPort.postMessage(parse(script));
}
上面的示例为每个 parseJSAsync() 调用生成一个 Worker 线程。在实践中,请使用worker线程池来执行此类任务。否则,创建 Worker 的开销可能会超过使用他们的收益。
Worker options
在创建worker程序和文件名时,我们可以将某些选项作为第二个参数。
argv:将被字符串化并附加到worker中的
process.argv的参数列表。这与workerData基本相似,但这些值在全局process.argv上可用,就像它们作为 CLI 选项传递给脚本一样。workerdata:我们要传递给worker线程的数据。该数据通过 HTML 结构化克隆算法在工作器中克隆。
transferList:ArrayBuffer | MessagePort | FileHandle | X509Certificate | Blob的项数组。如果在 workerData 中传递一个或多个类似 MessagePort 的对象,这些项需要一个 transferList 或 ERR_MISSING_MESSAGE_PORT_IN_TRANSFER_LIST 被抛出。下文将对此进行更多讨论。
env:如果设置,则指定 Worker 线程内部的
process.env初始值。作为特殊值,worker.SHARE_ENV可用于指定父线程和子线程共享其环境变量;在这种情况下,对一个线程process.env对象的更改也会影响另一个线程。resourceLimits:新 JS 引擎实例的一组可选资源限制。达到这些限制将导致 Worker 实例终止。这些限制只影响JS引擎,没有外部数据,包括ArrayBuffer。即使设置了这些限制,如果遇到全局内存不足的情况,进程仍然可能会中止。一些约束是
maxYoungGenerationSizeMb(主堆的最大大小,以MB为单位),maxOldGenerationSizeMbcodeRangeSizeMbstackSizeMb。name:可选的
name,附加到worker title以用于调试/识别目的,最终标题为[worker ${id}] ${name}。默认值为:''。
MessageChannel
对于线程之间的通信,两个组件非常重要,它们是在其上进行通信的通道和端口。首先,必须在通信之前建立通信通道。
const { MessageChannel } = require('node:worker_threads');
const { port1, port2 } = new MessageChannel();
port1.on('message', (message) => console.log('received', message));
port2.postMessage({ foo: 'bar' });
// Prints: received { foo: 'bar' } from the `port1.on('message')` listener
一个端口用于发送消息,另一个端口用于接收消息。基本上 port1 和 port2 为通道的两端。

MessagePort & MessagePort Events
在以前,我们用于parentPort.postMessage()将消息从 worker 发送到父级并使用worker.postMessage(),这是因为 parentPort 和 Worker 都是MessagePort类实例。这提供了 postMessage 和 message 事件,例如 message 和 close ,可以在这些事件上标记我们的回调。
message:为任何传入消息发出事件,
close:一旦通道的任何一侧断开连接,就会发出事件。
在线程之间传递数据的方法
- 克隆数据
有几种方法可以在两个线程之间传递数据。默认情况下,此数据是克隆的,即发送方和接收方都有自己的数据副本。这些数据是用“结构化克隆算法”克隆的。如果传递的数据深深地嵌套在内部,那么克隆数据将需要更多处理能力。因此,拥有数据副本并不总是最佳的。
- 传输数据
我们克服上述缺点的方法之一是传输数据。这可以通过使用transferList选项来实现。使用transferList,您可以将数据从发件人传递给收件人。不过,这样做将使发件人无法访问该数据。
transferList可以是ArrayBuffer、MessagePort和FileHandle对象的列表。传输后,它们在通道的发送端不再可用(即使它们不包含在值中)。目前不支持传输socket等句柄(在子进程中是可行的)。
- 共享数据
我们可以使用 SharedArray Buffer 在发送方和接收方之间共享相同的数据。
原子化
共享内存可以在worker线程或主线程中同时创建和更新,因此我们可能会面临竞争条件和同步的问题。为了避免这个问题,我们可以使用 Atomics。共享内存时,多个线程可以读写内存中的相同数据。原子操作可确保操作在下一个操作开始前完成,并且操作不会中断。
您不能将其与 new 运算符一起使用,也不能将 Atomics 对象作为函数调用。 Atomics 的所有属性和方法都是静态的(就像 Math 对象一样)。
Atomics.load():返回数组指定索引处的值。索引的吸气剂类型。Atomics.store(): 将值存储在数组的指定索引处。返回值。Atomics.and()/Atomics.or()/Atomics.sub()/Atomics.xor()/Atomics.add():按位运算Atomics.notify()/Atomics.wait():提供等待特定条件变为true的方法,通常用作阻塞结构。
现在让我们尝试用不同的方式传递数据
传输端口
当您想要传递传输列表中的端口时,这通常很有用。现在您可能会想我们为什么要这样做?因为这样你就可以重用消息通道。
parent.js
const { Worker, MessageChannel } = require('worker_threads');
const { port1, port2 } = new MessageChannel()
const worker = new Worker('./worker.js')
port1.on("message", msg => {
console.log(`Message from worker----> ${msg}`)
})
worker.postMessage({ port: port2}, [port2])
worker.js
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
msg.port.postMessage('Sent Hi from using transfered port')
})
输出:
Message from worker----> Sent Hi from using transfered port
使用Array buffer传输数据
Array buffer是一个固定长度且连续的内存区域,一旦声明长度就无法更改。你不能像普通数组一样直接访问里面的值,你需要一个叫做 dataview 的东西。
例如,如果我们声明 16 字节数组缓冲区(16 字节 === 128 位)。
const arrayBuffer = new ArrayBuffer(16)
现在,您将通过以下方式查看这些 128 位的数据。
- 可以将这 128位 视为 8 * 16 blocks,即 8 位整数数组。
const dataview = new Int8Array(arrayBuffer, 0 , 16)
- 将这 128位 视为 16 * 8 blocks,即 16 位整数数组
const dataview = new Int16Array(arrayBuffer, 0 , 8)
- 或将这 128位 视为 32 * 4 blocks,即 32 位整数数组。
const dataview = new Int32Array(arrayBuffer, 0 , 4)
这些 Int8Array 、 Int16Array 、 Int32Array 、 Int64Array 被称为类型数组(不同的方式来查看或代表ArrayBuffer中的数据)
parent.js
const { Worker } = require('worker_threads');
const worker = new Worker('./worker.js')
const arrayBuffer = new ArrayBuffer(16)
const dataview = new Int8Array(arrayBuffer, 0, 16) // all 0 by default
console.log('In Parent Before Transfer' + dataview)
worker.postMessage(dataview, [dataview.buffer])
// console.log('In Parent After Transfer' + dataview)
worker.js
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
console.log('In worker after transfer' + msg)
})
输出: 
这证明数据已经传输了。
如果取消对parent.js最后一行的注释,它将抛出以下错误,这证明parent.js无法访问已传输的数组缓冲区。

使用 SharedArray 缓冲区共享数据
尝试传输这个 Array buffer
parent.js
const { Worker } = require('worker_threads');
const worker = new Worker('./worker.js')
const sharedArrayBuffer = new SharedArrayBuffer(16)
const dataview = new Int8Array(sharedArrayBuffer, 0, 16) // all 0 by default
console.log('In Parent Before Sharing' + dataview)
worker.postMessage(dataview)
console.log('In Parent After Sharing' + dataview)
worker.js
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
console.log('In worker after Sharing' + msg)
})
输出: 
可以看到,来自父进程的最后一个log没有被"破坏",因为数据实际上是共享的,而不是被传输或克隆。
Worker 线程的使用陷阱
NodeJS Worker线程不是传统线程。如果您考虑像其他语言一样使用多线程,那么默认情况下线程需要共享相同的状态。 Nodejs Worker线程通过拥有自己的 V8、libuv 实例、事件循环和单独的堆,与其他Worker线程一样独立运行。
使用Worker线程进行IO是没有用的。使用 V8 引擎创建和维护Worker进程的开销比 Node 的异步 I/O 实现的效率低得多。
当性能节省的收益超过进程生成开销的代价时,应该使用Worker线程。
通过利用Worker线程共享池,我们能够提升效率并消除了不断创建新线程的需求。这种方法不仅节省时间和资源,还简化了Worker池的管理。像 Piscina 和 Poolifier 这样的库通过管理和处理 Worker池的复杂问题提供了方便的解决方案,使您能够专注于更重要的任务。
由于事件、相应的Worker线程以及产生的效果之间缺乏明确的联系,调试Worker线程可能非常具有挑战性。仅依靠
console.log()语句进行调试可能是一个乏味且容易出错的过程。但是,有一种解决方案可以增强您收到的诊断信息。通过将AsyncResource附加到池中,您可以获得全面的异步堆栈跟踪,以精确跟踪池中的活动。这个宝贵的工具可以让您观察特定情况时的完整事件序列。当在选择是使用子进程还是worker线程上感到困惑时,请记住,对于需要大量 CPU 工作的任务,请始终使用worker线程;如果要扩展您的应用程序,请使用子进程。
产生比核心数量更多的线程并不会真正给你带来很大的性能提升,因为 CPU 利用率会浪费在上下文切换本身上。这就是为什么他们说要小心使用线程池。
Piscina、Bree、Poolifier、WorkerPool 一些流行的库包装了模块以提供更方便的接口或更高级别的功能,例如线程池。
End.